


![[MAP Menu]](../img/huarphdr_21a.gif)
|
|
| |
|
|
|
The Kinetics subgroup was formerly under the direction of Neil Donahue, who developed and implemented most of the existing instruments, programs, and procedures. Visit the Kinetics subgroup website for more details.
Since Neil has left the Anderson Group, and the "organically grown" existing system has become somewhat cumbersome, confusing, and error-prone without its author around, the time seems ripe for a systematic overhaul. What follows is a systematic description of a revamped data collection and analysis system for the various Kinetics experiments, developed by David Corlette. The intent is to publish the system design for peer review and comments.
The kinetics subgroup has several different running "experiments" which utilize several different "instruments". The boundary lines between these categories are somewhat fuzzy, hence the quotation marks. In general, however, there are two types of data collection systems used by the kinetics subgroup:
The QNX DAS instruments are designed to take real-time flow data of running experiments, and are sometimes used in conjunction with FTIR/Spectroscopy for taking occasional spectra during a run. HPF1 usually uses the mattson, and HPF3 uses the bruker. The ringdown will probably consist of a QNX DAS part and additional ringdown measurements.
The feature that defines the QNX DAS instruments is that the various detectors and measurements are made and controlled using the QNX DAS software, which produces a standardized telemetry stream of data. The FTIR-type instruments typically produce proprietary formats that need to be processed by vendor-supplied software.
Note that the discussion that follows reflects the current state of affairs; this will be modified soon to reflect the new software, which is what is documented in the man pages.
The main Kinetics instruments use the QNX Data Aquisition Sotware to collect measurements and control the run of the experiments. Since extensive documentation of this software is available, I won't go into detail here. Usually, once the instrument is physically set up, the experimenter will issue a "doit" command on the flight node (the flight node actually runs the flight algorithm and contains the DAQ hardware; the doit command can be run on another node (a "GSE"), but typically this is not done). This starts up the generic algorithm that runs the experiment and takes measurements and places them in the telemetry stream. While the experiment is running, the experimenter can issue various commands to affect the operation of the instrument. Meanwhile, the telemetry stream is being logged to disk locally.
The most significant command is "run begin", which starts an individual "run" (a set of operations to examine a particular reaction etc). This is the set of observations that the experimenter is interested in. During a run, an experimenter may also do some FTIR measurements, which will later be correlated with the run. There is some facility for running different "types" of runs, e.g. for calibrations and whatnot, but in general this is poorly matched with actual usage, difficult to maintain, and not documented.
HPF1 does two kinds of runs: "Kinetics" runs and "Product Study" runs. For the most part, Kinetics runs can be automatically processed on the Linux side, because calculating a rate constant is really all that needs to be done. Product runs, however, make heavy use of IR data and graphing, so typically analyzing such runs is done manually.
There are additionaly types of runs: OH_plume, Zero, LaserCheck. These are primarily for calibration.
HPF1 currently has a facility for manually specifying a run type; the text name for the run is placed in the file "run.type" (I believe that OH_plume runs are specified this way). HPF2 has no such facility.
In addition, the experimenter specifies other relevant parameters, such as the radical under study, the run model, the manifold, bulb, and size. I don't know what all these are, but they are specified in "run.schedule" which is read line by line, with each line corresponding to each run. These get set and read into the output of pipeext.
Once the run is over, the experimenter will issue a "run end" to terminate that run, and at that point may shut down the instrument or start another run. There are various other commands, such as aborts and whatnot, but them's the basics.
Of course, it's not that simple. The Kinetics subgroup does not work on the actual telemetry data stream itself, but on a processed variant thereof. To get that data set up, several steps are needed:
Of course, there are any number of ways to implement the above processing steps, but since the telemetry stream resides on QNX and the text files need to end up on the Linux/NeXT systems, there must be some sort of network transfer at some point.
The data heirachy deserves particular attention, since it is designed to allow for efficient analysis, backup, recovery, etc. Here's a map:
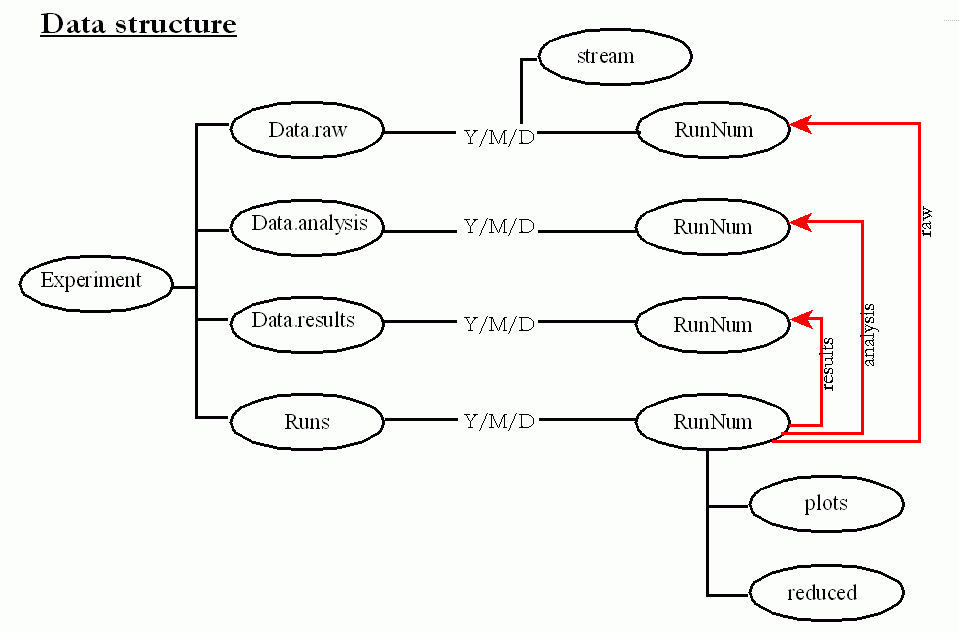
The essential feature to notice is that the "Runs" directory links together several parallel trees. This allows each tree to be treated differently w.r.t. backup, permissions, etc, but provide one place in which work can be done without needing long pathnames (the IR data is also linked into the Runs directory as "ir" and "ir.reduced" (not shown)).
The data analysis techniques used are still somewhat fuzzy to me, but it seems that the most important calculations involve rate constants and processing spectra files, for "kinetics" type runs and "product" type runs, respectively. Each of these calculations may involve all sorts of data reduction, plot generation, correlation, etc etc etc. Most if this work is done by "PSPlot", a somewhat obscure program which does the large matrix calculations needed and produces the PostScript output. Also, in order for this all to function, the data heirarchy must be set up correctly.
In the ideal world, the data system would recognize which type of run was being run, and automatically invoke the correct analysis scripts. Unfortunately, there are always customizations that need to be made, and it hasn't been sufficiently reduced to the state where a small set of config files would be sufficient to define all the necessary parameters. In some simple cases, however, analyses can be run automatically; indeed, there is some level of automation in development that would enable automatic termination/generation of runs, so eventually a whole series of runs could be initiated and analyzed with a single command.
As mentioned, the existing system has been "grown", so that there are all sorts of cobbled together bits and pieces, bits of functionality that were never fully implemented or abandoned in favor of others, bits smushed together when they should be separated (significantly, all data for all experiments is combined into a single data heirarchy rather than separated!), etc. Although many of the features of the current system are highly evolved and extremely functional, a revamping of the system is called for.
The first phase of the new system design must start with a statement of goals. The new system must:
I'm now going to focus in on the individual aspects of the data system, and talk about how each piece should be designed, and how it should relate to the next piece.
The data collection system design is primarily determined by the design of the QNX DAS software, which is pretty firm at this point. The aspects of configuration which should be revisited have mostly to do with the data definitions, and the introduction of new features.
For instance, the existing telemetry definitions support various types of runs, including "Test", "Zero", "LaserCheck", etc. There even seems to be a facility for including an arbitrary run type definition. Some effort should be made to determine which experiments actually need which run types, and provide easy ways of setting which one is currently underway (perhaps a GUI-like selection script?). The same goes for the "run.schedule" used by kinetics runs; perhaps a front-end to quickly define a set of runs to be completed? Finally, the use of hardware vs. software status bits could perhaps be revisited to make things a bit simpler.
After a discussion with Norton, we've come up with the following design, 1st cut:
The key here is that there is no explicit runType dependent stuff in dataRecv or any of the other scripts in /Data/scripts/sbin. Those scripts just know a simple set of things to try, and use the $runType variable to set how they behave, but the explicit behavior is usually set by external scripts or files.
Additionally, the newer graphics features of QNX windows should be exploited. At the moment, watching the progress of a run requires either reading data off the text state screens, or running commands on the Linux/NeXT side to see trends of certain variables. The facility exists to display much of this simple information in QNX Windows graphical screens, and implementing these (which will require a HW upgrade) would be nice.
Basically, the system as it currently stands works pretty well, but it could use a bit of touchup and review, and some new features. It might also be a good idea to document the various experiments, the various types of runs they do, and why.
The data processing step is the "meat" of what I'm working on right now. The current design violates virtually all the design considerations I laid out earlier, so a new system is in order.
One of the major problems is the requirement to pass the data across the network to the Linux/NeXT platform. At the moment, this uses ssh; other suggestions would use NFS to access the data. This seems like a monumental waste of resources to me; telemetry streams are designed to pass across media like networks, and it merely requires setting up the correct system to use a lightweight, simple protocol to pass the data through the net. This setup has in fact been developed by Norton and Eileen as part of the DAS, although it hasn't been completely refined as of yet. The basic strategy is to use a pair of programs, Inetin and Inetout, to handle the transfer in as simple and robust a way as possible. Furthermore, the system can fairly easily be modified to "replay" the data in case the network fails; after all, the data is still logged locally to the QNX side, and a set of scripts is available to extract past data and play it back into the data ring.
To explain how the system works is pretty simple. Recall the basic DAS design:
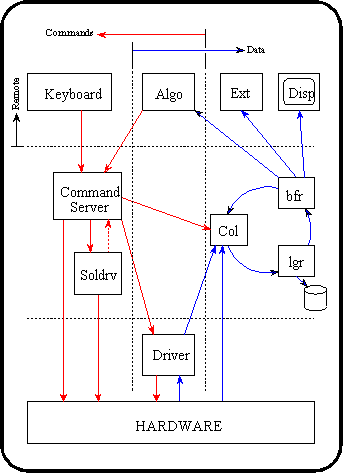
Under the existing design, "pipeext" reads from the buffer (perhaps like the "Ext" in the diagram), and then uses ssh to transfer data over to "dataReceiver[n]" on the Linux/NeXT side. The new design would not run pipeext on the QNX side; instead, the experimenter would run a "doit" script on the L/N side as well, which would start up "Inetin". Inetin would in turn initiate a connection to the QNX node, which would automatically start up Inetout. Inetout is fed from the buffer and passes data to "Inetin". "Inetin" then acts like a ring client (e.g. like "Col"), and so pipeext should be written to read from "Inetin" and pass the data to "dataRecv" (e.g. it will replace "bfr" in some sense). One significant change would be that pipeext should now extract the current date from the telemetry stream and pass that to "dataRecv", rather than having "dataRecv" calculate the date from some wierd-ass algorithm. This allows replayed data to very easily be processed into the correct place (replayed data is replayed by "rdr", which replaces "Col" on the QNX side. Otherwise, everything else is the same (at least Inetout/in are)).
Once the data is on the L/N side, it is the job of "dataRecv" to store it in the correct locations and process it. "dataRecv" itself is as simple as possible; it really only writes out the stream of raw data and each run, and then forks other scripts to do the rest of the work. The old version tried to determine how to process the data itself and went through all sorts of convolutions to do so. In addition, dataRecv takes a single argument, which is the date. This allows replayed data to be correctly stored. It also handles the case where for some reason the stream data is stored correctly but the runs are not created; catting the stream data through dataRecv again once the problem is fixed should be sufficient to set up the run directories and initiate processing from that point.
Runs are typically started by a "!Begin" command appearing in the data stream. As mentioned before, there are actually several types of scripts that can be initiated, including arbitrarily named ones. The old script tried to handle each type of script in "dataReceiver"; the new one will hopefully provide a generic mechanism for defining how to handle each type of script (definitions in "Experiment.config" on the L/N side will provide configuration information). All actual type-dependent processing is done by other scripts, of course.
The "other scripts" I keep mentioning are as follows:
Note that all of these scripts can be restarted by simple changing to the correct raw data directory and initiating "[scriptName] `pwd`". The script uses the current path information to find the data files, experiment name, etc, and Experiment.config to find everything else.
The creation of the links and the recording of the run in various places is pretty standard, but some significant changes will hopefully be made to the rest of it. First of all, a generic mechanism will hopefully be created to specify which type of run is being processed, and, based on that, which type of calibrations, checks, and analysis should be done. If arbitrary runTypes are run on the QNX side, then we need to define how they should be processed on the L/N side. Initially, this information will perhaps be encoded into the scripts as it is now, but eventually I hope to extract this out into definitions in the Experiment.config file.
The data analysis is currently mostly done using PSPlot, and despite the supposed automation of the process, for the most part it seems is done manually. I'd like to change this slightly (over time) in the following ways:
The next thing to do is to look in detail how the scripts work and how the configuration file formats work.
The QNX DAS instruments use the same basic telemetry system as the rest of our flight program, but for the kinetics group the data is processed and used differently. The basic operations for taking data go as follows:
The end result of the above procedure is that the data from the experiment is stored in three places: 1) On QNX, under the standard "YYMMDD.R/logxxxx/logxxxx" heirarchy, 2) On a Kinetics system, in a "raw.dat" file for the entire day, 3) in a separate directory for just that run, in a "raw.dat" file that is a subset of the day's "raw.dat". Data types 1) and 2) are really just for backup; assuming the data in the individual RunNum doesn't get corrupted or lost, it will never be used. For that reason, the QNX data can just be collected for a while (several months), then burned to CD and deleted.
Note that the RunNum for HPF is 000-199; for HPF2 is 200-399.
The new system should use the following paths:
Where RunNum is 000-999
The relevant files are:
How this data is analyzed is described below.
The FTIR/Spectroscopy instruments are used both in conjunction with the QNX DAS systems and stand-alone. Each instrument is typically a unique, vendor-specific system, with vendor-specific software:
The Mattson uses WinFIRST to collect data. Due to vagaries of PC-NFS, data is logged into /Data/hpf/mattson/first/thisrun (or thisrun.reduced for reduced data). Once a set of data (typically associated with a "run" under HPF) is collected, the script "moveIRData" is run which moves the data to:
/Data/hpf/mattson/first/<year>/<mon>/<date>/<RunNum>/ and
/Data/hpf/mattson/first/reduced/<year>/<mon>/<date>/<RunNum>/
The new system should use the paths:
How this data is used in conjunction with the HPF data is described below.
The Bruker is a complete mystery to me at this time. A Windows system does the DAQ and writes the results to a local disk. These files are transferred through Novell.
The Ringdown system is currently being developed by Greg Engel. Because of the huge quantities of data that are collected, Data.raw will likely not be created; the data will be reduced in memory and written to a Data.reduced heirarchy. A Windows system will do the actual DAQ.
The data heirarchy described above (Data.raw and descendents) is intended to segregate the raw data from the processed results. No actual work is done in the Data.raw diectory; instead, a parallel "Runs" tree is created with links into the raw data. There are also parallel data trees for results and analysis, each of which are linked into the Runs tree. The structure looks like this:
In order to create this structure, a simple script is run which creates the relevant links. Other scripts are run to create links to any Mattson or Bruker IR data for a particular run.
Since Neil is no longer a member of the group, it has become my (David Corlette's) job to redo some of the Kinetics setup to make it understandable to non-Neil mortals. To this end, I am researching the existing system exhaustively and trying to think about better ways to design it for robustness and simplicity (which is not to say the existing system is non-functional; quite the opposite. But the existing system was developed "organically" over time, and is therefore somewhat labyrinthine and has vestiges of old, obsoleted ideas included in it).
The QNX data acquisition side is fairly mature, having been the focus of intensive development by Norton and Eileen. Neatening up the experimental specification and including other TM commands and algorithms might be in order, but for now the system works as is.
One key development in the QNX DAS arena is the "inetin" and "inetout" functions, which will allow generic TCPIP connections to the telemetry stream. This should supplant the use of ssh et al for the data stream since it will be more robust, simpler, and less resource-draining. The basic design works something like this:
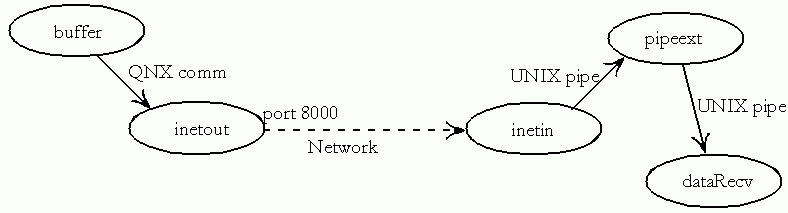
The "inetout" and "inetin" programs are part of the standard DNX DAS software, although "inetin" will have to be compiled on the receiving end and use the special QNX libraries ported by Eileen. The pipeext program was written by Neil to convert the standard TM data stream to a Kinetics-processable format; this just needs to get moved from the QNX side to the Kinetics machine side. And finally, dataRecv already exists, although it will probably be extensively modified to handle multiple experiments and be more robust.
The current way of getting data into the Kinetics system is to use dataReceiverN, where N refers to the experiment. The new design would replace that with a single script, dataRecv, which would detect from the TM channel which experiment's data is being collected and log it to the correct place. Additionally, the current script tends to perform a lot of processing inside the script itself; the new script will attempt to invoke subprograms to do much of the work in a non-blocking fashion s.t. the fundamental logging portion of the script remains unaffected. Here's an attempt at a control flow diagram for the new script.
| last updated: Thu Aug 7 13:49:54 2003 | webmaster@huarp.harvard.edu |
| Copyright 2002 by the President and Fellows of Harvard College | |
| [Home] [People] [More Info] [Research Areas] [Field Missions] [Engineering] | |